AIR科研|AIR打造虚拟医院,实现AI医生自我进化
清华大学智能产业研究院(AIR)与清华大学计算机科学与技术系合作构建了虚拟医院Agent Hospital,提出了医学智能体自我进化方法MedAgent-Zero,通过在虚拟医院中产生大量无需人工标注的数据,让医学智能体不断提升医疗能力,并在真实世界数据集得到验证。Agent Hospital中所有的病人、护士和医生均由大模型驱动的自主智能体扮演,对发病、分诊、挂号、问诊、检查、诊断、开药、康复和随访的“院前-院中-院后”闭环流程进行模拟。Agent Hospital基于知识库与基础模型对虚拟病人的疾病产生与发展过程进行模拟。虚拟医生在Agent Hospital中进行学习(即阅读医学文献)与实践(即与虚拟病人交互并做诊疗决策),不断从成功诊疗案例中总结经验、从失败案例中反思教训,在多个诊疗任务上实现准确率持续提升。在诊疗近万名虚拟病人后(人类医生大约需要2年时间),虚拟医生能够在MedQA数据集呼吸道疾病子集上超越当前最好的方法,达到93.06%的准确率。该研究由AIR马为之助理研究员与AIR执行院长、计算机系副系主任刘洋教授担任论文共同通讯作者,在arXiv上公开后受到海内外人工智能社区和医学社区的广泛关注和讨论。
· 论文标题:Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents · 论文链接: https://arxiv.org/pdf/2405.02957v1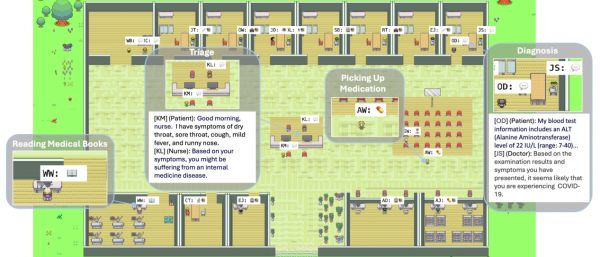
Agent Hospital概览
研究背景
近年来,大规模语言模型蓬勃发展,基于大语言模型的智能体技术备受关注。已有研究利用智能体技术实现了真实世界模拟,包括“斯坦福小镇”、“狼人杀游戏”等交互和博弈场景;同时,智能体技术也被用在解决各类任务的调度规划、协作过程,但这个过程大都依赖于高质量人工标注数据的支持。因此带来的研究问题是,真实环境模拟能否助力智能体的任务处理能力提升。
智慧医疗因其场景的重要性和应用价值广受关注,研究团队高度关注大语言模型和智能体技术在医疗场景的应用研究。针对上述研究问题,团队认为真实的模型环境能够助力智能体的任务能力提升和进化,因此开展了结合真实世界模拟和医学能力提升的Agent Hospital研究。在本工作中,团队致力于构建医院模拟环境,探索医学智能体在该环境下的自主进化。目的是让智能体能够像人类医生一样在诊疗和学习过程中自主积累医学知识,实现医学能力的不断进化。Agent Hospital构建
研究团队首先致力于利用大模型智能体模拟真实世界的关键医疗环节。在Agent Hospital中,团队设计并覆盖了从疾病产生到康复的8个典型场景,即:发病、分诊、挂号、问诊、检查、诊断、开药和康复,且患者会主动参与随访反馈。所有的环节流程均由大模型支持,在其中的角色间能够进行自主交互。
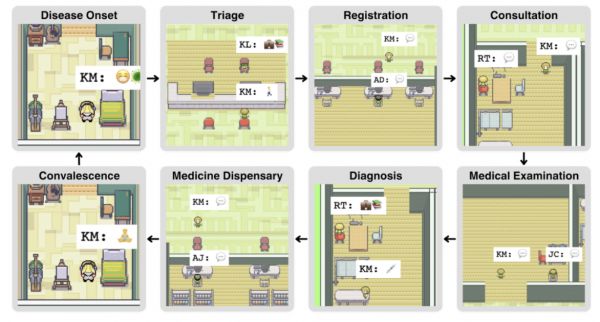
上图展示了闭环的诊疗环节:当病人智能体角色Kenneth Morgan患病后,他会前往医院求助。分诊护士Katherine Li了解Morgan的症状进行分析后,将他分诊到具体科室就诊。Morgan会根据医嘱完成挂号、咨询、医学检查后,医生Robert会给他最终的诊断和治疗方案,Morgan将会根据医嘱回家休息并反馈给医院康复情况,直至下次生病再前往医院。
从上述示例中可以看到,研究团队为医院主要设计了两类角色:医护人员和患者。所有的角色信息都是由大模型(GPT-3.5)生成,因而可以很轻松地扩展增加。部分角色的具体信息如下图所示,35岁的患者Kenneth Morgan当前患有急性鼻炎,且有高血压病史,当前有持续呕吐等一系列症状;Zhao Lei则是一名经验丰富的影像科医生,内科医生Elise Martin具备优秀的交流能力,擅长内科急/慢性疾病的诊断、治疗。这些完整的人物信息背景提升了医院模拟的真实性。

在上述医疗模拟过程中,疾病的产生是其中的关键。具体来说,当前的病历信息是由大语言模型结合医学知识为患者生成完整的病历,包括疾病类型、症状、持续时间、各项检查结果等(具体内容可见论文附录)。需要注意的是,为了尽可能保证整个模拟流程的准确性,患者智能体只会感知到自己的疾病症状但不知道具体疾病,而医生智能体则只能通过和患者智能体对话问诊和开具检查来了解信息。患者智能体需要进行的检查、所患疾病类型和疾病严重程度判断将作为三个关键任务来评价医学智能体对虚拟病人的诊疗能力。
智能体自我进化
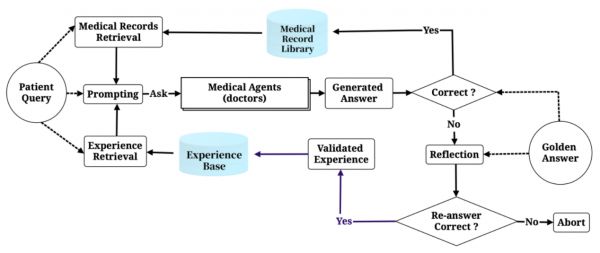
MedAgent-Zero策略流程示意图
如上图所示,MedAgent-Zero的进化方式包括两种途径: 1) 从成功案例中总结经验,对于能够答对的诊疗问题,智能体会像人类医生一样进行病例库经验积累; 2) 从失败案例中反思教训,在回答错误时,智能体会主动进行错误反思并进行反思。 如果反思的经验教训能够帮助智能体回答对该问题,它将被保留下来并存储在经验库中。最终,研究团队将在虚拟数据上的训练过程中进行上述两方面的积累进化。在每次推理过程中,智能体从两个库中检索最相似的内容并将其加入到Prompt中进行In-context Learning,并根据回答的正确和错误分别进行病历积累或者是经验总结,从而实现智能体能力的持续提升。
医学能力评价
在虚拟医院中,研究团队构造了上万名虚拟病人的病历用于医学智能体的自主进化实验,包括甲流、乙流、新冠等8个呼吸道相关疾病,涉及十余种不同的医学检查。按照人类医生一周治疗约100名病人计算,人类医生可能需要花两年诊断10000名病人,但是智能体医生只需要几天就可以完成。
团队主要从两方面对虚拟医院中的医学智能体进行能力评价。首先是在虚拟环境中的医学能力评价:如下图所示,在医学智能体的训练过程中(左图),随着诊疗病人的增加,医学智能体在三个关键任务上的准确率持续上升并逐渐趋于平稳;而针对500个测试病历的实验则发现(右图),在诊疗病人数量增加的过程中智能体准确率略有波动,但整体呈现上升趋势。
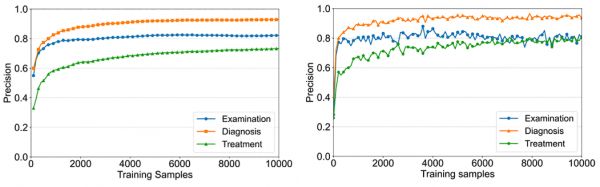
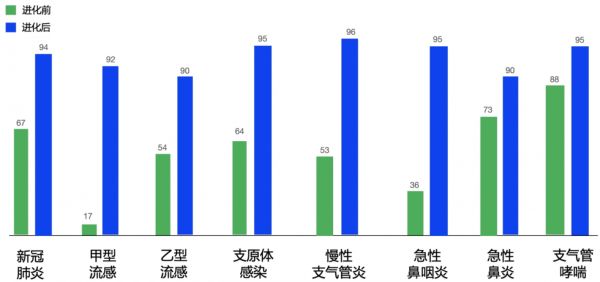
智能体进化前后在不同疾病的诊断表现
另一方面,团队使用了外部数据集MedQA的呼吸道疾病子集用于评价医学智能体在真实世界的医学能力。令人惊讶的是,即便在智能体进化的过程中没有使用任何人工标注的数据,在诊疗近万名病人后,医学智能体能够在该数据集上超越当前最好的方法,达到了最高93.06%的准确率,验证了模拟环境中医学智能体自主进化的有效性。
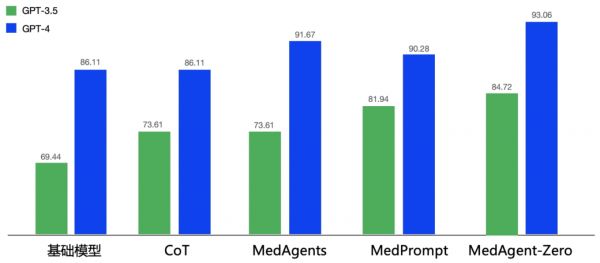
不同方法在MedQA子集上的正确率
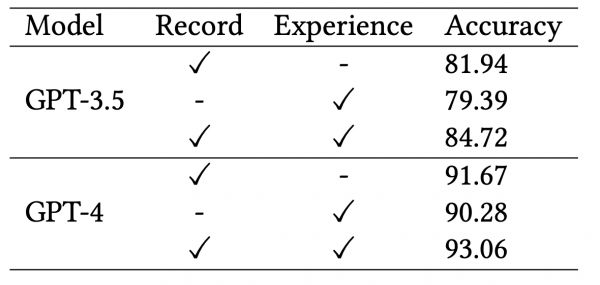
此外,研究团队开展了消融实验验证,结果表明不管是从成功中积累的样例还是从失败中总结的经验都有助于提升模型的医学能力。
通讯作者简介


刘洋,清华大学万国数据教授、智能产业研究院(AIR)执行院长、计算机系副系主任,国家杰出青年基金获得者。研究方向为人工智能、自然语言处理与智慧医疗。个人主页:https://nlp.csai.tsinghua.edu.cn/~ly。
相关知识
AIR观点|聂再清:数据驱动的个性化营养健康管理是慢病管理的核心
3999元!云米AI健康监测马桶Air上线 居然还能测血压
Current status and prospects of air purification and disinfection technology
AIR学术|韩腾:新型感知与反馈自然交互技术
Health Impact Assessment of Air Pollution from Road Traffic Sources in China
Mass Concentrations, Source Analysis and Health Risk Assessment of Some Emerging Air Pollutants
AI虚拟教练助你练出人鱼线,揭秘Keep AI运动技术实力
Ai健身运动中心!虚拟教练打造“运动处方”
心景科技:精神心理VR数字疗法,助力实现“在虚拟中训练,在现实中康复”—维科号
心景科技:精神心理VR数字疗法,助力实现“在虚拟中训练,在现实中康复”
网址: AIR科研|AIR打造虚拟医院,实现AI医生自我进化 https://m.trfsz.com/newsview572644.html