一种用于失语症患者康复训练专用的语音识别方法与流程
本发明涉及语音识别技术领域,尤其涉及一种用于失语症患者康复训练专用的语音识别方法。
背景技术:
失语症是一种后天获得性神经语言障碍,表现为患者产生或理解语言的能力受到损害,包括听、说、读、写四个方面。研究发现,失语症患者的生活质量非常差,排名倒数第一,紧随其后的才是癌症和老年痴呆症患者。为了消除或减轻这种影响,失语症患者和他们的护理人员积极寻求康复治疗。失语症的主要康复手段为言语训练法,然而,这是一个资源密集型的过程,在评估和治疗中,至少需要一位语言病理学家。这一要求很难满足,因为失语症群体数量庞大,而且医疗资源有限。针对这种情况,计算机辅助治疗可以起到很好分担治疗压力的作用。但是,计算机辅助治疗失语症主要流行于欧美国家,国内的相关研究工作比较陈旧且为数不多。本发明的目的是训练一个失语症患者的自动语音识别模型,以支持患者的康复训练和辅助交流,本发明满足世界卫生组织提出的家庭康复和早期支持出院(earlysupporteddischarge,esd)计划。
针对失语症患者的计算机辅助治疗,如果采用通用的语音识别模型,不能满足失语症患者的语音识别要求,因为患者跟健康人的说话特征有所不同,患者会出现发音费力、音位错误等现象。
技术实现要素:
本发明实施例所要解决的技术问题在于,提供一种用于失语症患者康复训练专用的语音识别方法。可用于失语症患者的康复训练、言语评估和辅助交流中。
为了解决上述技术问题,本发明实施例提供了一种用于失语症患者康复训练专用的语音识别方法,包括以下步骤:
步骤1:录制包含失语症患者和健康被试者的语音材料;
步骤2:将所述语音材料中的语音信号转换成特征矩阵,所述特征矩阵的大小为n*51,其中n为语音信号个数,51为信号特征维度,包括2维时域特征、3维频域特征、39维倒谱域特征、7维图像特征;
步骤3:使用特征选择确认使用所述特征矩阵得到最优结果;
步骤4:在将所述特征矩阵输入机器学习算法支持向量机训练所述语音识别模型之前,进行z-score数据标准化处理;
步骤5:将所述特征矩阵输入机器学习算法支持向量机中进行学习,构建出用于失语症患者言语康复的语音识别模型;
步骤6:将待识别语音转换为所述特征矩阵,使用所述语音识别模型预测识别结果。
进一步地,所述步骤2将所述语音信号转换成特征矩阵的步骤包括:
步骤2.1:使用matlab函数audiodatastore读取所述语音信号,获得语音标签和采样率,所述语音标签的形式为n*1向量,n为语音信号个数;
步骤2.2:获取时域特征,检测所述语音信号中的时域波形图,设置幅度阈值lcthreshold为0.05,提取语音信号的过零率;使用matlab函数f_pitch计算出语音的基音频率;
步骤2.3:获取频域特征,检测语音信号的频谱图及其包络,提取包络的前三个峰值;
步骤2.4:获取倒谱域特征,使用matlab函数mfcc计算出语音的倒谱域特征,其中梅尔倒谱系数的第一维使用信号能量的对数值替代;
步骤2.5:获取图像特征,使用短时傅里叶变换将语音信号转换成具有时频域特征的语谱图,使用matlab函数regionprops检测语音的图像特征;
步骤2.6:将上述时域特征、频域特征、倒谱域特征、图像特征放入n*51的所述特征矩阵中,其中n表示语音信号的个数,51表示语音信号的特征维度。
更进一步地,所述步骤5将所述特征矩阵输入机器学习算法支持向量机中进行学习的步骤包括:
步骤5.1:使用matlab函数templatesvm创建一个默认的svm模板t;
步骤5.2:在多分类学习器fitcecoc中输入步骤2的所述语音标签和特征矩阵,设置交叉验证折数为5折,训练出所述语音识别模型。
更进一步地,所述步骤3使用特征选择的步骤包括:
将步骤2中的所述语音标签和特征矩阵导入matlab的快速分类学习器classificationlearner中,通过手动自由选择特征组合,最终确认使用步骤2所述特征矩阵得到最优结果。
更进一步地,所述步骤4进行z-score数据标准化处理的步骤包括:
将所述特征矩阵按列求取均值xj和标准差sj,然后根据公式zij=(xij-xj)/sj计算得出标准化后的数值,其中,xij为特征矩阵中的原始值。
更进一步地,所述语音信号内容中国康复研究中心标准失语症检查表中的关键词汇。
实施本发明实施例,具有如下有益效果:本发明采用的语音特征向量以及组合健康人和患者数据进行训练模型的方法,可以有效地提高失语症患者的语音识别率,构建的模型可以应用于失语症患者的康复训练、言语评估和辅助交流中。
附图说明
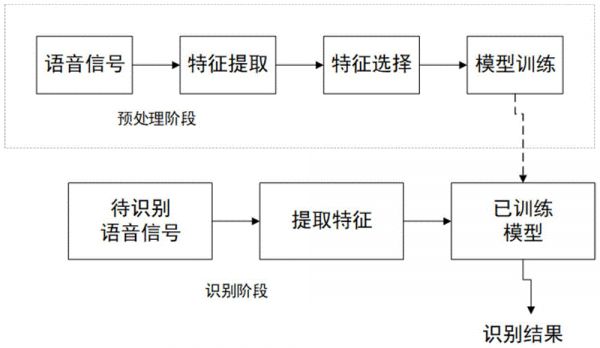
图1是本发明语音识别框架图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
本发明实施例的一种用于失语症患者康复训练专用的语音识别方法,通过以下步骤进行。
步骤a,招募符合要求的失语症患者(共13名)和健康被试(共34名)录制用于训练模型的语音材料。语音材料选自中国康复研究中心标准失语症检查表(chineserehabilitationresearchcenterstandardaphasiaexamination,crrcae)中的20个关键词汇,包含10个动词和10个名词以及中文6个基本元音ā,ō,ē,ī,ū,ǖ,语料均采用普通话录制。其中,健康被试的语料可以提高模型的识别性能,因为部分失语症患者的发音障碍并不严重,比较接近正常人;crrcae为失语症评估临床量表。
步骤b,将步骤a录制的语音信号(包括患者和健康被试)转换成特征矩阵。
一,使用matlab函数“audiodatastore”读取语音信号,获得语音标签和采样率,语音标签的形式为n*1向量,n为语音信号个数。同时设置帧长为256,帧移为196;
二,检测语音信号的时域波形图,设置幅度阈值lcthreshold为0.05,提取语音信号与x=lcthreshold的交点数,即过零率。同时使用matlab函数“f_pitch”计算出语音的基音频率;
三,检测语音信号的频谱图及其包络,提取包络的前三个峰值,即共振峰;
四,使用matlab函数“mfcc”计算出语音的倒谱域特征,其中梅尔倒谱系数的第一维使用信号能量的对数值替代。此特征为r*c矩阵,其中,r代表语音信号的帧数,c代表特征维度。然后,对此特征矩阵取均值,得到1*c的特征向量;
五,基于短时傅里叶变换(short-timefouriertransform,stft),将语音信号转换成具有时频域特征的语谱图,使用matlab函数“regionprops”检测图像特征,即语音的时频域特征;
六,将上述所有特征放入一个n*51的矩阵中,其中n表示语音信号的个数,51表示语音信号的特征维度,即每一行代表一个语音信号,每一列代表一种特征向量。
上述语音特征共51维,其中包括2维时域特征:过零率、基音频率;3维频域特征:第一共振峰、第二共振峰、第三共振峰;39维倒谱域特征:13维梅尔倒谱系数(mel-frequencycepstralcoefficients,mfcc)、13维mfcc一阶差分值、13维mfcc二阶差分值;7维时频域特征:频率峰值检测区域的质心、主频率峰值宽度、方向角、检测区域中的实际像素数、能量强度的最大值、能量强度的最小值、能量强度的平均值。时频域特征是语音通过短时傅里叶变换,在其语谱图上提取出来的图像特征,不同的语音在语谱图上会表现出不同的能量分布,这种分布差异性决定了其具有较好的语音区分度。
步骤c,将语音特征向量输入机器学习算法支持向量机(supportvectormachine,svm)中进行学习,构建出用于失语症患者言语康复的语音识别模型。
学习过程如下:
一,使用matlab函数“templatesvm”创建一个默认的svm模板t;
二,在多分类学习器“fitcecoc”中输入步骤b的语音标签和语音特征矩阵,此两者具有相同的行数,呈现一一对应的关系。
然后,设置学习器为模板t,设置交叉验证折数为5折。按此设置即可训练出用于失语症患者的语音识别模型,最后将其保存为matlab脚本代码。
在得到最终识别效果较好的模型之前,进行了特征选择,方法如下:将步骤b中的语音标签和语音特征矩阵导入matlab的快速分类学习器“classificationlearner”中,通过手动自由选择特征组合,最终确认使用步骤b所述的51维特征可以得到最优结果。
在将特征矩阵输入svm训练之前,进行了z-score数据标准化处理。具体如下:特征矩阵按列求取均值xj和标准差sj,然后根据公式zij=(xij-xj)/sj计算得出标准化后的数值,其中,xij为特征矩阵中的原始值。
支持向量机算法可以包括线性支持向量机、二次支持向量机及其变种和组合。
模型训练完毕后(前述均为模型训练过程),假设有一待识别语音,将其转换成步骤b所述的51维特征向量序列后,用“predict”函数即可用此模型来预测识别结果。
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
相关知识
言语康复训练对脑卒中失语症患者的临床护理应用
言语治疗的训练方法:失语患者如何重新开口交流?学习下
脑卒中后失语患者的语言康复护理
国际言语治疗的训练方法,助失语患者重获新声
浅谈失语症儿童的语言康复训练
运动性失语症康复训练方法
如何进行失语语言康复训练?
语言认知康复训练方法
言语障碍患者的康复PPT
语言康复训练方法
网址: 一种用于失语症患者康复训练专用的语音识别方法与流程 https://m.trfsz.com/newsview681661.html